driver = webdriver.Edge()
driver.get("https://www.booking.com/searchresults.zh-tw.html?ss=%E5%8F%B0%E5%8C%97&checkin=2023-10-10&checkout=2023-10-12&group_adults=2&no_rooms=1&group_children=0")
沒錯還是那個booking,可以藉由這次觀察一下,beautifulsoup跟selenium的差別
titles = driver.find_elements(By.CSS_SELECTOR, 'div[data-testid="title"]')
這邊要注意,如果想要尋找的標籤是動態產生出來的話,就需要用到這種By.CSS_SELECTOR
for title in titles:
print(titles.text)
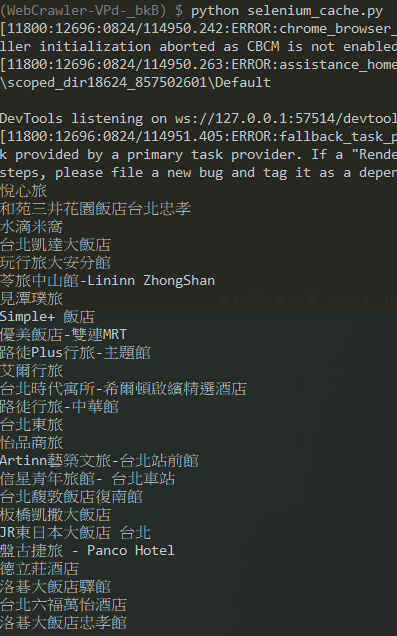
啊哈!!!成功啦
下一篇來告訴你另一個方法去搜尋

